Explaining what learned models predict: A Short Essay
Scientific essay accompanying the Master’s in Data Engineering & Analytics application, Technische Universität München
In which cases can we trust machine learning models and when is caution required?
Introduction
Machine learning models boast such predictive capabilities that hearing a novel or updated model that broke yet another benchmark really comes as no surprise. This is largely due to the surge of research the field enjoys, accompanied by constant advances in computer hardware. However, there remains a crucial question to be answered: To what extent can we trust these models? While being firmly convinced that machine intelligence constitutes the predominant direction in which solutions to several problems shall be searched, in this essay I will present my ideas on why blindly trusting ML models would not account for wise choice, yet.
During recent years, ML models such as Deep Neural Networks (DNN) relentlessly evolve, being found nowadays at the heart of numerous applications, ranging from Computer Vision and object detection up to Natural Language Processing and Understanding — in key areas like medicine and justice. In some cases, such as image classification, machines have exhibited performance better or on par with humans [6, 9] (at least in the absence of distortions [16] and low-SNR signals [17]). But as these models evolve, the more complex they become, making the task of understanding them and verifying their outputs more and more difficult. This, in turn, makes these models less trustworthy, posing a hurdle to their widespread adoption.

Figure 1: Google Trends plot for searches relating to the term “explainable ai”. The thick trendline reveals the constantly-increasing interest of the research community around the Explainability and Interpretability of ML models.
Source: Google Trends, Google Inc. (https://trends.google.com)
Definition and Importance of Explainability in Machine Learning Models
The process of explaining what learned models predict is itself an intricate one — it even lacks a concrete definition [14]. Nevertheless, there are increasingly more efforts in understanding what models — especially the ones trained in a supervised manner — predict and how they learn. This is also depicted in the Google Trends plot of the keyword “explainable ai” (figure 1) and is grounded on the strong correlation between a model’s “transparency” (i.e. user explainability [7]) and its trustworthiness when applied to real-world scenarios and tasks [4, 15]. In what follows and according to [14], model explainability (or interpretability which is used interchangeably in this essay) is defined with respect to two principal desired properties, namely Transparency and Post-hoc Interpretability. Although the former ensures an intuitive explanation of the model’s output and operations, it is so constraining considering the size and complexity of today’s models, that the focus is almost exclusively on the latter to interpret machine/deep-learning models resembling black-boxes.
Before proceeding in reviewing some of the prevailing techniques in interpreting black-box models (i.e. Post-hoc interpretability), it would be worth noting some cases where trained models can be considered transparent and therefore trustworthy by design. Models that fall in this category are principally simple machine-learning models, such as linear regressors (e.g. the constrained least-squares or lasso regressor as in [3]) and simple decision trees that have been long-thought as more interpretable compared to deep neural networks. Classification trees [1] as another example are not only readily interpretable (since labels can be recursively assigned to all intermediate nodes, and therefore an explanation can be produced for every output by following the path and echoing labels) but may also help in inferring causal relationships in observational variables [18].
Post-hoc Interpretability of Trained Models
Rocketing of computing performance that modern parallelization hardware has allowed, has made machine learning models — particularly deep learning models — resemble black boxes. Under no circumstances, however, should we categorize these models as not interpretable by default because doing so is like admitting that a great portion of today’s frontiers in machine learning success and applicability should not be considered reliable. Consequently, many methods have been proposed in assessing model interpretability after the training phase (i.e. post-hoc) and without much digging into the lower-level mechanics of the model. Two major such groups of techniques are presented in the succeeding paragraphs, wherein the use of DNN as template models is assumed since the representations learned by such models are often incomprehensible to humans.
Explanations along with Model Outputs
Using surrogate models to explain predictions of deep networks has been a prevalent interpretability technique at the early stages of their adoption, remaining until today an important way to validate models and enhance their reliability. Initial endeavors exploited the explainability power of decision trees. In one such work, Craven et al. proposed at 1996 Trepan [2], a method that uses a trained neural network as a black-box for extracting comprehensible, symbolic representations of how the model makes predictions. A more recent example of explainability with surrogate models was the joint training of a reinforcement learner and a Recurrent Neural Network (RNN) proposed by Kerning et al. [13]. In their approach, the learner model was trained to minimize an objective function while the RNN was used to map the model’s state into a textual explanation describing the followed strategy.


Figure 2: LRP demo on image classification. The right image, resulting from LRP, contributes significantly in understanding how the model reached its prediction, making it more easily verifiable and more user-friendly.
Source: Explainable AI Demos, Fraunhofer Institute for Telecommunications (https://lrpserver.hhi.fraunhofer.de)
Probably a milestone in black-box model interpretability was a general technique proposed by Bach et al. for explaining predictions of Convolutional Neural Networks (CNN), known as Layer-wise Relevance Propagation (LRP) [10, 11], where the graph structure of DNN was exploited. In particular, after the output for a given image was computed they back-propagated the prediction scores to find which parts of the input image chiefly affected those scores. As can be seen in the Figure 2, this technique provides valuable insights on how the predictions on a per-sample basis are made, thus helping in model validation and trust establishment.
Feature Visualizations of CNNs
Another set of techniques to generate Post-hoc interpretations is focused on searching the input space to retrieve samples that maximize the activations of certain neurons or layers of DNN. Trained CNN, for instance, are known to be feature extractors [12], and therefore maximizing activation of learned convolutional filters is equivalent to finding features in observations that are recognized by those filters. Probably the most popular method for visualizing what image classifiers have learned is Activation Maximization [5, 8].
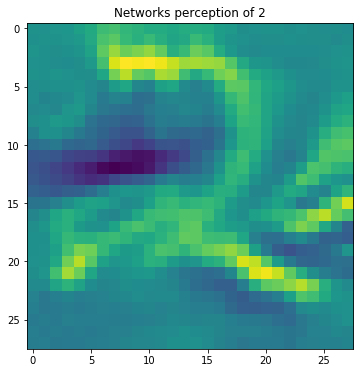
Figure 3: Visualization of the input image that maximizes activation of a particular neuron of a MNIST digits CNN classifier. It can be clearly seen that this particular neuron gets mostly activated when an image of the digit “2” enters the network. Activation-maximization here is employed in order to understand how the CNN classifier makes predictions.
Activation Maximization fixes the weights of the entire network and tries to update the input image (i.e its pixel values) such that activation at a particular layer of the CNN is maximized. The basic idea is that by knowing what input maximally activates a layer, we may interpret and extract information on what this layer is trying to capture and consequently explain the model’s output. This technique is better illustrated in the Figure 3, where a specific neuron of a CNN classifier was found to by maximally active when an image of the digit “2” is given as input.
Conclusion
As more and more ML systems are being deployed in real-world applications and processes, the need for more transparent — or ideally self-explained — models is becoming apparent. And while the aforementioned methods for black-box interpretability have helped in extracting information on how models learn and predict there are still several limitations that prevent us from being confident enough that learned models decide in the same way a human does and that algorithmic errors or bias in ML have perished. All in all, I am inclined to believe that research in explainable AI has to progress at the same pace as the one in the ML itself, so as for trustful and reliable models to be developed and to supersede humans in critical decision processes.
References
For the entire list of references, please see the attached PDF file.